At Altertable, we're building a unified, always-on data platform. This post breaks down our storage and query architecture, why we're leaning into the Apache Iceberg paradigm, and why DuckDB is emerging as our real-time query engine of choice. (See also: our full technical stack)
One Data Lake, Two Different Workloads
To serve both product analytics and business intelligence from day one, our platform must deeply understand customer data. That starts with ingesting it from every corner of a company’s stack:
- Real-time web and product event tracking (e.g., user clicks, page views, custom app events)
- Scheduled ETL pipelines that sync structured data from internal production databases
- Drag-and-drop uploads for manual files, including JSON and CSV formats
- Programmatic data pushes via a JDBC driver
This data stream powers two distinct workloads:
- Interactive UI queries – supporting human-led exploration through our web dashboard, where users investigate trends, build funnels, and analyze real-time behaviors to drive decisions
- Persistent AI agents – autonomous workers that continuously monitor the data, detect anomalies, segment users, and proactively surface insights before anyone initiates a query
Interactive UI queries demand millisecond-level responsiveness to ensure a fluid and engaging experience. Speed isn't just a luxury: it's the difference between insight and inertia. In contrast, AI agents work behind the scenes and can afford longer latencies (ranging from seconds to minutes) while continuously processing and analyzing data. The challenge lies in efficiently serving both use cases without duplicating or fragmenting the underlying data lake.
Storage Format Matters
Apache Iceberg is a modern table format built to handle the needs of large-scale analytics. What makes it stand out is how it delivers features that traditional data warehouses often struggle with:
- ACID compliance for appends, updates, and deletes
- Safe and flexible schema changes over time
- Built-in support for time travel, enabling historical queries and rollbacks
From an infrastructure perspective, what's particularly compelling is Iceberg's clean separation of storage and compute:
- It stores data in heavily compressed Parquet files on object storage like S3 or local disks — cheap, scalable, and immutable
- Metadata lives alongside it in formats like JSON and Avro, also on object storage
- Query engines stay stateless and horizontally scalable: no need for ZooKeeper, replica coordination, or other heavyweight infra
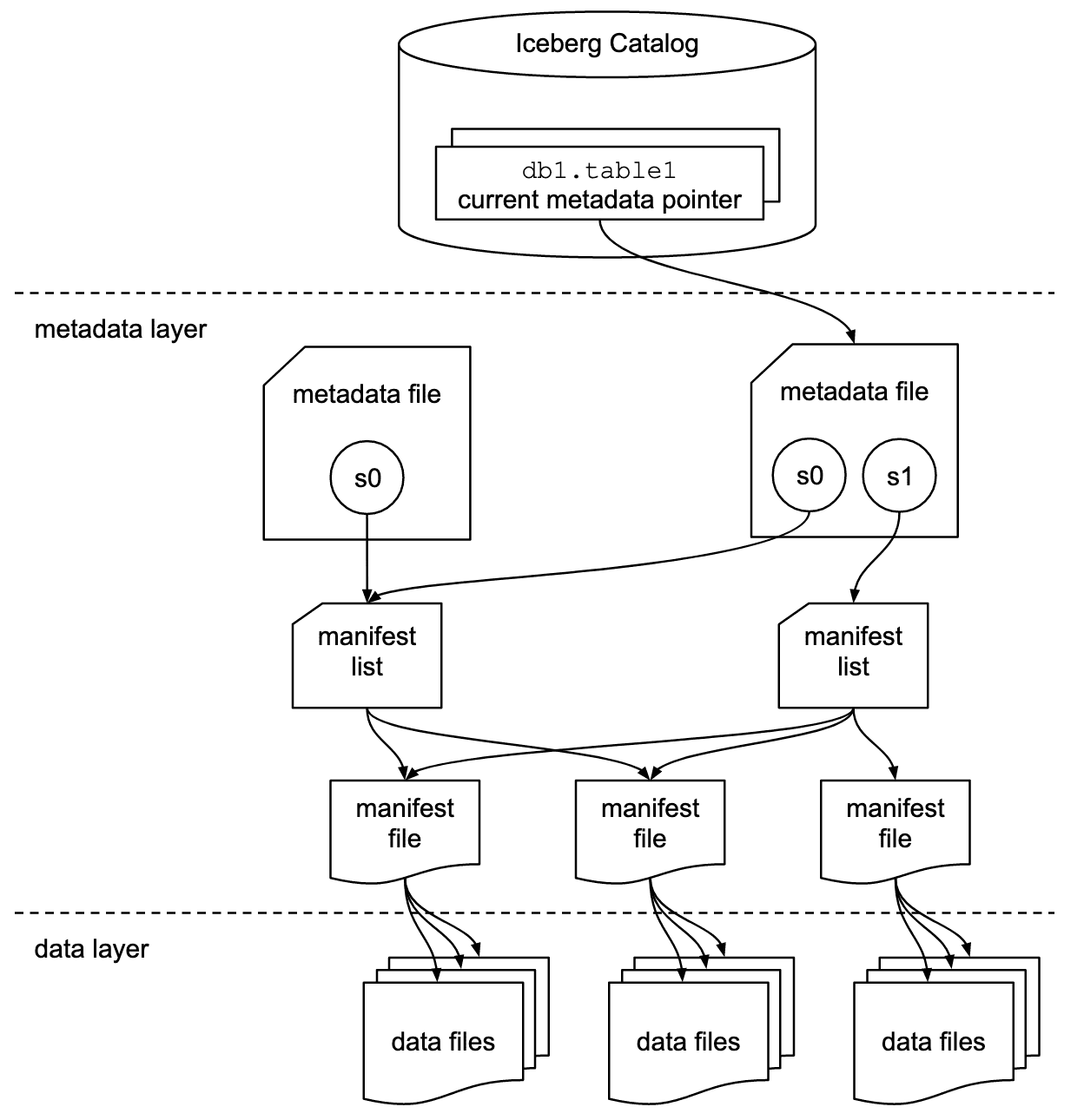
This architecture makes Iceberg a solid foundation for modern analytics workloads.
The Latency Wall: Choose the Right Query Engine
Even though Parquet is optimized for analytics and Iceberg can narrow down queries using partition pruning, querying data stored in S3 still comes with inherent latency. This is due to S3 being object storage, which isn't built for fast, small reads like a traditional database. To work around this, most real-world query engines use some kind of caching to store frequently accessed data or metadata closer to the compute layer — reducing the time it takes to return results.
Our goal is to minimize the overhead of the query engine itself to serve interactive UI queries with subsecond response times.
Trino: Great for Scale, Less So for Real-Time
We started with Trino, a distributed SQL engine built for high-throughput, large-scale querying. It's Iceberg-native, supports ANSI SQL, and excels at scanning gigabytes or terabytes of data across a cluster.
But for our interactive queries that power real-time dashboards and user-facing analytics, Trino introduced just enough latency to disrupt the responsive experience we aim to deliver.
Here's what we found:
- Trino distributes queries across multiple nodes in a cluster, which is ideal for scanning large datasets, but introduces unnecessary coordination delays for the small, fast queries common in real-time dashboards
- A significant portion of the latency comes from query planning alone — often taking up to 300ms just to generate the execution plan
- Because Trino runs on the Java Virtual Machine (JVM), there's additional delay from cold starts and the time it takes for just-in-time (JIT) compilation to optimize execution
To reduce this latency, we experimented with a few tuning strategies as well as constraining Trino to single-threaded execution for simple queries. These helped, but only to a point. Trino is built for throughput, not latency-critical workloads. It remains an excellent fit for analytical jobs where queries can take a few seconds but for real-time experiences we needed something faster and lighter.
DuckDB: A Real-Time Path Forward
That brought us to DuckDB: a fast, in-process analytical database purpose-built for speed and simplicity.
DuckDB feels like SQLite for analytics:
- It runs in-process, with no server to manage
- It's optimized for low-latency, memory-resident execution
- It's commonly used for local analysis, format conversion, and interactive SQL
DuckDB includes a modular extension system that enables dynamic loading of integrations like iceberg at runtime. This gives us exactly what we need for real-time analytics:
- SQL parsing and execution
- Native traversal of Iceberg metadata, including catalogs and manifests
- Direct reading of Parquet files stored on S3
In other words, DuckDB gives us a minimal path from SQL → Iceberg metadata → S3 data, and is particularly well-suited for workloads where a single node can process everything in memory.
To reduce network roundtrips, we pair DuckDB with its cache_httpfs extension, which caches both Iceberg metadata and data to disk. This makes object storage behave more like local disk while retaining the durability and scale of S3.
With this setup, real-time querying becomes viable. We can serve interactive dashboards and analytics with subsecond latency and no infrastructure sprawl.
DuckLake: the New Cool Kid on the Block
We're still exploring, testing, and benchmarking potential improvements, but one promising development is DuckLake: DuckDB's newly introduced integrated data lake and catalog format.
DuckLake takes a different approach to metadata. Unlike Iceberg, which stores metadata as JSON and Avro files on object storage, DuckLake writes all metadata to a transactional catalog database (typically Postgres). This shift has big implications for real-time performance: metadata queries become faster and no longer require multiple S3 roundtrips.
As the DuckDB team points out, a transactional database is already required to guarantee ACID operations — so it makes sense to fully leverage it instead of falling back on file-based metadata management. And importantly, the volume of metadata is tiny compared to the volume of data stored in S3, making this design both efficient and practical.
Another standout feature for our real-time use case is data inlining: DuckLake can store small inserts directly in the catalog database rather than writing them immediately to Parquet. This reduces write-to-read latency and is especially useful for recent or frequently accessed data.
We're watching DuckLake closely as it evolves. It could offer an even simpler, lower-latency path to real-time analytics without giving up durability or scale.
The Road Ahead
This is a fast-moving ecosystem and we're building at the edge of it. Combining open formats like Iceberg, emerging engines like DuckDB, and experimental layers like DuckLake, we're assembling a new kind of stack: one built not just for scale, but for speed, interactivity, and always-on insight. For engineers who care about performance and systems, this is one of the most exciting places to be.